מ-Context ל-AI Engineering Workflow


20 דקות קריאה
אמ;לק
בפוסטים הקודמים בסדרה, עסקתי בבעיה הבסיסית של עבודה עם AI: איך מונעים ממנו לעבוד מתוך קונקסט חלקי, לנחש החלטות מערכתיות, ולייצר קוד שנראה נכון אבל לא באמת מתאים למערכת.
השלב הבא הוא לא רק לתת ל-AI יותר Context. השלב הבא הוא לבנות סביבו תהליך הנדסי.
כאן נכנסים שני frameworks מעניינים במיוחד:
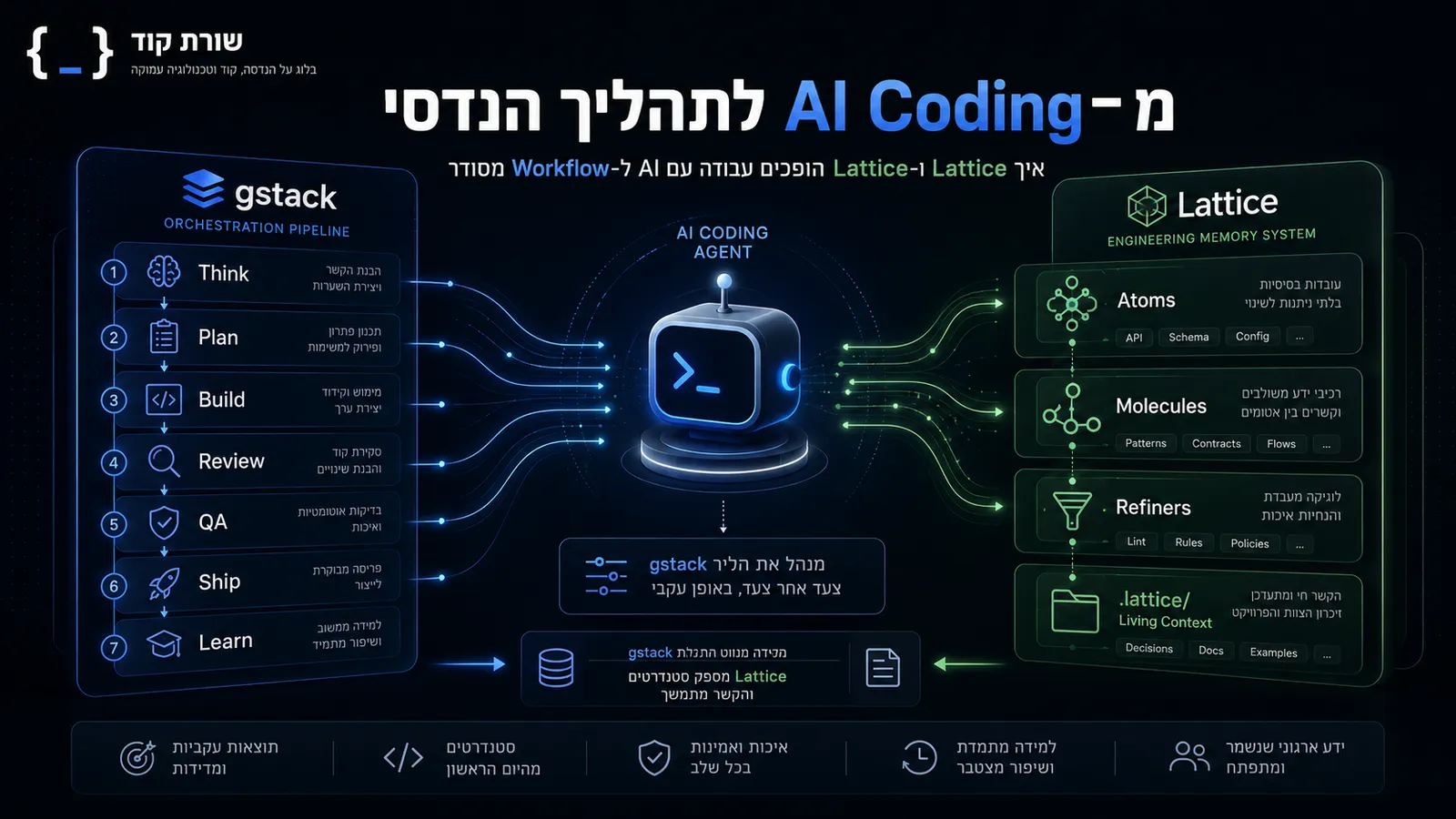
gstack הוא framework פתוח שמגדיר סט של slash commands ו-skills לעבודה עם AI coding agents. במקום לבקש מה-AI ״תבנה לי פיצ׳ר״, gstack מפרק את העבודה לתפקידים ושלבים: product thinking, engineering review, design review, code review, QA, security, ו-shipping. אפשר לחשוב עליו כעל שכבת אורכסטרציה שמנסה להפוך AI coding ל-delivery pipeline.
Lattice הוא framework של composable AI skills שמנסה לקודד engineering discipline לתוך תהליך העבודה. הוא בנוי מ-Atoms, Molecules, Guardrails, Refiners קטנים, workflows מרובי שלבים, ותהליכים שמייצרים סטנדרטים ספציפיים לפרויקט. בנוסף, Lattice משתמש בתיקיית .lattice/ כשכבת קונטקסט חיה - מקום שבו נשמרים ה-design, דרישות, סטנדרטים, code reviews, החלטות ולמידה מתמשכת.
אם הפוסטים הקודמים היו על איך לא לאבד קונטקסט, הפוסט הזה הוא על איך להפוך קונטקסט לתהליך עבודה שחוזר על עצמו.
במילים פשוטות:
gstack נותן ל-AI תפקיד בתוך תהליך הפיתוח.
Lattice נותן ל-AI זיכרון הנדסי, סטנדרטים ו-guardrails.
ביחד, הם מחליפים עבודה אד-הוק עם AI ב-AI Engineering Workflow.
רקע
עבודה עם AI בפיתוח תוכנה מתחילה בדרך כלל בצורה תמימה: נותנים משימה, מקבלים קוד, עושים review, מתקנים, שוב מריצים, ואז מנסים להבין למה שינוי קטן הפך ל-diff של 1,200 שורות.
הבעיה היא לא שה-AI ״לא יודע לתכנת״. במקרים רבים הוא יודע לייצר קוד סביר מאוד. הבעיה היא שהוא לא בהכרח יודע את הדברים שהופכים קוד לסביר בתוך המערכת שלנו:
איזה שכבות מותר להן לדבר אחת עם השניה.
איפה עובר הגבול בין domain logic ל-infrastructure.
אילו APIs נחשבים יציבים ואילו לא
איפה צריך idempotency.
מה נחשב test טוב בצוות.
מה הם ה-failure modes שכבר שרפו אותנו בעבר.
מתי אסור להוסיף abstraction גם אם זה נראה ״נקי״.
אלו לא פרטים קטנים. אלו בדיוק הדברים שמבדילים בין קוד שעובר compile לבין שינוי שאפשר להכניס ל-production בלי להזמין לעצמנו incident עם קפה שחור ב- 02:17.
בפוסטים הקודמים בבלוג דיברנו על קונטקסט כבסיס: איך גורמים ל-AI להבין יותר מהמערכת, איך מייצרים סביבת עבודה ברורה, ואיך מונעים ממנו לעבוד מתוך תמונה חלקית. אבל קונטקסט לבדו לא מספיק.
גם מפתח אנושי עם גישה מלאה לריפו עדיין צריך תהליך: להבין דרישות, לתכנן, לקבל פידבק, לכתוב טסטים, לעבור review, לבדוק התנהגות, וללמוד מהשינוי למחזור הבא.
אותו דבר נכון ל-AI.
וכאן gstack ו-Lattice נכנסים לתמונה.
מה זה gstack?
gstack הוא framework פתוח לעבדוה עם AI coding agents, שמבוסס על רעיון פשוט: במקום להתייחס ל-AI כאל ״מתכנת אחד שעושה הכל״, מחלקים את תהליך העבודה לשלבים ולתפקידים. בדומה ל-Personas מהפוסטים הקודמים.
ב-gstack יש פקודות כמו:
/office-hours
/plan-ceo-review
/plan-eng-review
/review
/qa
/ship
כל אחת מהן מייצגת שלב אחר בתהליך. לא כל שלב כותב קוד. להפך - חלק מהשלבים נועדו למנוע כתיבת קוד מוקדמת מדי.
/office-hoursעוזר לחדד את הבעיה/plan-ceo-reviewמאתגר את הערך המוצרי וה-scope./plan-eng-reviewבודק מקרי קצה, data flow, ארכיטקטורה, ו-test plan./reviewעובר על הדלתא אחרי המימוש./qaבודק התנהגות./shipמסכם את השינוי לקרא merge או release.
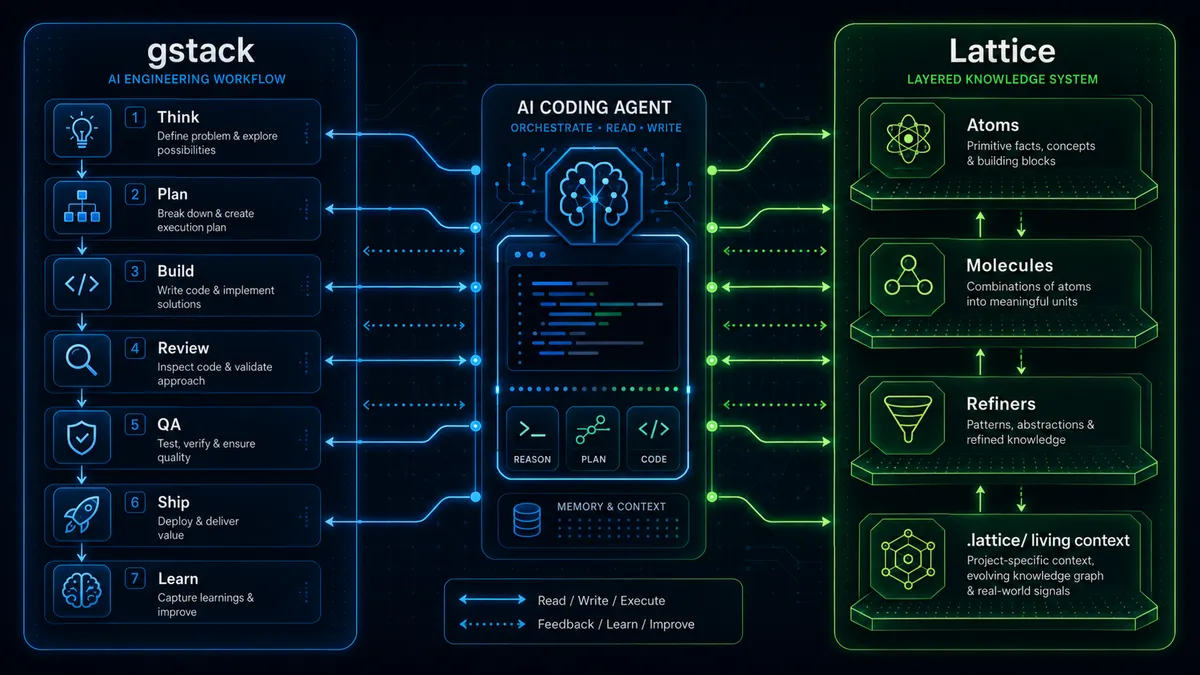
כלומר, gstack לא מנסה רק לשפר את הפרומפט שלכם. הוא מנסה להכניס את ה-AI לתוך מחזור פיתוח.
במקום:
Prompt → Code → Review → Pain
מקבלים משהו קרוב יותר ל:
Think → Plan → Build → Review → Test → Ship → Learn
וזה שינוי משמעותי. כי ברגע שה-AI עובד בתוך שלבים, אפשר לעצור אותו לפני המימוש, להכריח אותו להפיק artifacts, לבדוק הנחות, ולהשתמש בתוצרים של שלב אחד כקלט לשלב הבא.
מה זה Lattice?
Lattice מגיע מאותה בעיה, אבל מזווית אחרת.
אם gstack שואל ״איזה תפקיד ה-AI ממלא עכשיו?"
Lattice שואל ״לפי אילו סטנדרטים הנדסיים ה-AI עובד?״
Lattice הוא framework של composable AI skills. הוא בנוי משלוש שכבות עיקריות:
Atoms - guardrails קטנים וממוקדים. למשל - clean code, architecture, secure-coding, test-quality, design-first ו-context-anchoring.
Molecules - workflows שמרכיבים כמה Atoms יחד. למשל, requirement-forge, design-blueprint, code-forge, bug-fix, refactor-safely
Refiners - תהליכים שמייצרים סטנדרטים ספציפיים לפרויקט. למשל architecture standards, review standards, או requirement standards.
החלק החשוב הוא ש-Lattice לא מסתפק בהנחיות כלליות כמו ״כתוב קוד נקי״. הוא מנסה להפוך את ההנחיות למסמכים חיים בתוך הריפו, תחת תיקיית .lattice/. לדוגמה:
.lattice/
├── config.yaml
├── standards/
│ ├── architecture.md
│ ├── clean-code.md
│ ├── secure-coding.md
│ ├── test-quality.md
│ └── review-standards.md
├── requirements/
├── context/
├── reviews/
└── learnings/
זו נקודה קריטית: קונטקסט לא נשאר רק בתוך צ׳אט זמני. הוא הופך ל-artifact.
ה-AI לא אמור ״לזכור בערך״ מה החלטנו. הוא אמור לקרוא את הסטנדרטים, לעבוד לפיהם, לעדכן קונטקסט, ולייצר למידה למחזור הבא.
Lattice גם מתכתב ישירות עם סדרת המאמרים של Martin Fowler / Thoughtworks על צמצום החיכוך בעבודה עם AI-assisted development. הסדרה מדברת על patterns כמו Knowledge Priming, Design-First Collaboration, Context Anchoring, Encoding Team Standards ו-Feedback Flywheel.
הרעיון המרכזי שם מאוד רלוונטי: AI coding assistant צריך קונטקסט, סטנדרטים, onboarding, ופידבק בדיוק כמו מפתח חדש שנכנס לצוות. ההבדל הוא שאצל AI, אם לא כותבים את הדברים במפורש - הוא ישלים לבד. והוא ישלים בביטחון.
וזה תמיד הרגע שבו ה-PR מתחיל להיראות כמו ניסוי חברתי.
איך זה עובד?
כדי להבין את הערך של gstack ו-Lattice, צריך להפריד בין שלושה דברים שלפעמים מתערבבים:
קונטקסט - מה ה-AI יודע על המערכת.
תהליך - באיזה סדר הוא עובד
סטנדרטים - לפי אילו כללים הוא מקבל החלטות.
עבודה נאיבית עם AI נותנת בעיקר פרומפט. לפעמים פרומט ארוך, לפעמים פרומפט מושקע, אבל עדיין פרומפט.
פרומפט טוב יכול לעזור. אבל פרומפט הוא לא תהליך. הוא לא מחזיק את ה-state בצורה אמינה. הוא לא מוודא שהייתה חשיבה לפני המימוש. הוא לא מבטיח שהחלטות design נשמרות. והוא לא יוצרת תהליך למידה ופידבק.
gstack ו-Lattice מוסיפים שתי שכבות שחסרות בדרך כלל.
gstack מוסיף אורכסטרציה.
Lattice מוסיף engineering memory.
נניח שאנחנו רוצים לבנות פיצ׳ר חדש: refund workflow עבור חשבוניות ששולמו.
בגישה נאיבית, אפשר לכתוב:
Build a refund workflow for paid invoices.
Include validation, audit log, event publishing, and admin status view.
זה נשמע סביר. אבל בפועל, חסרון כאן המון שאלות:
מהם המצבים האפשריים של invoice?
האם refund יכול להיות חלקי?
מי רשאי לבצע אותו?
מה קורה אם external payment provider מחזיר timeout?
האם דחיפה ל-queue הוא חלק מה-transaction?
איך מונעים החזר כפול?
איפה נשמר ה-audit log?
האם ה-UI קורא projection או source of truth?
מה ה-rollback behavior
אילו events כבר קיימים במערכת?
AI טוב יכול לנחש חלק מזה. הבעיה היא שאנחנו לא רוצים שהוא ינחש. אנחנו רוצים שהוא יעצור, יפרק, יתכנן, ויבקש אישור.
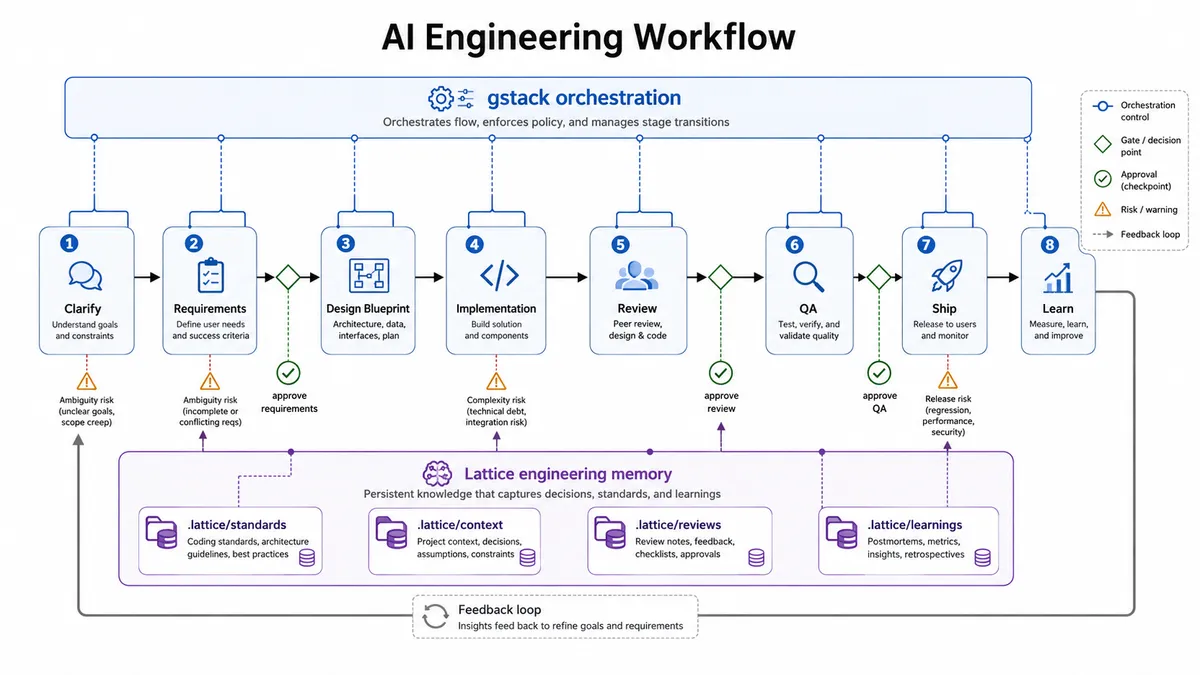
כאן gstack מכניס סדר:
/office-hours
↓
/plan-ceo-review
↓
/plan-eng-review
↓
build
↓
/review
↓
/qa
↓
/ship
במקביל, Lattice מוודא שהעבודה מתבססת על standards ו-context:
/requirement-forge
↓
/design-blueprint
↓
/code-forge
↓
/review
↓
learnings saved into .lattice/
אפשר לחשוב על השילוב כך:
gstack = מה השלב הבא בתהליך?
Lattice = אילו כללים והקשרים חלים על השלב הזה?
בשלב המימוש, Lattice יכול להפעיל Atoms כמו: architecture, clean-code, secure-coding, test-quality, context-anchoring.
בשלב ה-review, gstack יכול להפעיל review role שבודק bugs, scope, ו-production risk, בזמן ש-Lattice משווה את הדלתא ל-standards ול-learnings שכבר נאספו.
התוצאה היא workflow שבו ה-AI כבר לא ״רץ על הקוד״. הוא מתקדם דרך שערים:
Unclear request
↓
Structured requirement
↓
Approved design
↓
Constrained implementation
↓
Delta review
↓
Behavior validation
↓
Shipping summary
↓
Reusable learning
זה עדיין לא מבטל review אנושי. ממש לא. אבל זה משנה את המקום שבו האדם נכנס לתמונה.
במקום לבזבז review על ״למה שמת לוגיקה בתוך adapter?״, אפשר להתמקד בשאלות החשובות יותר:
האם זה ה-design הנכון?
האם ה-scope מוצדק?
האם ההתנהגות העסקית מלאה
האם ה-failure modes אמיתיים?
האם השינוי מתאים לכיוון הארכיטקטוני של המערכת?
וזה בדיוק המקום שבו AI הופך מכלי שמייצר קוד לכלי שמייצר leverage הנדסי.
דוגמה מעשית
נבנה דוגמה קונקרטית ל-workflow שמבוסס רק על gstack ו-Lattice.
נניח שיש לנו סרביס ב-TypeScript שאחראי על billing. אנחנו רוצים להוסיף פיצ׳ר חדש למערכת שיאפשר תמיכה ב-refund לחשבוניות ששולמו. המערכת כוללת HTTP API, שכבת application, domain logic, postgreSQL, queue publishing ו-admin UI שקורא refund state.
המטרה היא לא ״לתת ל-AI לבנות refund״.
המטרה היא להוביל אותו דרך תהליך שבו כל שלב מייצר artifact ברור.
שלב 1: הגדרת Lattice context
אם זה ריפו חדש ש-Lattice לא ראה, אתם יכולים להריץ את ה-skill הבא: /lattice-init. בזמן הזה Lattice ילמד את הריפו שלכם, באיזה טכנולוגיות אתם משתשמים, איזו ארכיטקטורה וכו׳. הוא ישאל גם אם הוא לא בטוח. התוצאה תהיה מבנה בסיסי כזה:
.lattice/
├── config.yaml
├── standards/
│ ├── knowledge-base.md
│ ├── architecture.md
│ ├── clean-code.md
│ ├── secure-coding.md
│ ├── test-quality.md
│ ├── requirement-standards.md
│ └── review-standards.md
├── requirements/
├── context/
├── reviews/
└── learnings/
└── operational-learnings.md
קובץ .lattice/config.yaml יכול להיראות כך:
version: 1
paths:
knowledge_base: .lattice/standards/knowledge-base.md
architecture: .lattice/standards/architecture.md
clean_code: .lattice/standards/clean-code.md
secure_coding: .lattice/standards/secure-coding.md
test_quality: .lattice/standards/test-quality.md
requirement_standards: .lattice/standards/requirement-standards.md
review_standards: .lattice/standards/review-standards.md
operational_learnings: .lattice/learnings/operational-learnings.md
השלב הבא הוא להגדיר את כל ה-refiners. למשל התוצאה של ה-architecture יכולה להיראות כך:
---
mode: overlay
---
# Architecture Standards
## Layering
Allowed dependency direction:
- `interfaces/http` → `application`
- `interfaces/workers` → `application`
- `application` → `domain`
- `application` → ports
- `infrastructure` → ports
- `infrastructure` → external SDKs
Forbidden:
- `domain` importing `infrastructure`
- HTTP controllers querying PostgreSQL directly
- queue consumers duplicating business rules
- application services depending directly on vendor SDKs
## Messaging
Every queue publisher or consumer must define:
- event contract
- idempotency strategy
- retry behavior
- dead-letter behavior
- observability signals
- poison-message ownership
## External Calls
Every external API call must include:
- timeout
- bounded retry policy
- error classification
- correlation id
- clear fallback or fail-fast behavior
## Money Movement
Any operation that moves, refunds, captures, reserves, or releases money must define:
- authorization boundary
- audit trail
- idempotency key
- consistency model
- reconciliation strategy
זה מסמך חשוב. הוא לא רק "style guide". הוא boundary contract.
כאשר AI מייצר קוד, אנחנו רוצים שהכללים האלו ילוו אותו. אם הוא מנסה לקרוא ישירות ל-PostgreSQL מתוך HTTP controller, זו הפרה. אם הוא מוסיף queue event בלי idempotency, זו הפרה. אם הוא מטפל ב-refund בלי audit trail, זו הפרה.
שלב 2: פתיחת עבודה עם gstack
מתחילים לא מקוד: אלא משאלה:
/office-hours
We need to add a refund workflow for paid invoices.
Goal:
Allow admins to request a full or partial refund for an already paid invoice.
Initial requirements:
- Validate invoice state.
- Prevent duplicate refunds.
- Write an audit trail.
- Publish RefundRequested event.
- Expose refund status to the admin UI.
Do not propose implementation yet.
Clarify product scope, missing assumptions, and risk areas.
כאן אנחנו לא מבקשים קוד. אנחנו מבקשים friction. כלומר אנחנו רוצים שה-AI יתאגר את הבקשה.
פלט טוב בשלב הזה אמור לכלול שאלות כמו:
- Are partial refunds allowed more than once?
- Who can approve a refund?
- Is refund execution synchronous or asynchronous?
- What happens if the payment provider accepts the refund but event publishing fails?
- Does the admin UI need real-time status or eventual consistency?
- What is the expected audit format?
- Are refunds reversible?
זה שלב קריטי כי הוא מנוע מאיתנו להגיע למימוש עם ambiguity שמתחפש לדרישה.
שלב 3: דרישות עם Lattice
עכשיו משתמשים ב-Lattice כדי להפוך את הבקשה למסמך דרישות:
/requirement-forge
Create a structured requirement for the refund workflow.
Input:
Admins can request a full or partial refund for a paid invoice.
The system must validate invoice state, prevent duplicate refunds,
write an audit trail, publish RefundRequested, and expose refund status.
Use project requirement standards.
Persist the result under .lattice/requirements/refund-workflow.md.
Explicitly include:
- business rules
- authorization rules
- state transitions
- API expectations
- event expectations
- failure modes
- open questions
פלט אפשרי:
# Refund Workflow Requirement
## Capability
Admins can request a full or partial refund for a paid invoice.
## Business Rules
- Refund can only be requested for invoices in `PAID` state.
- Total refunded amount must not exceed paid amount.
- Duplicate refund requests must be rejected or deduplicated.
- Every refund request must be auditable.
- Refund execution is asynchronous.
## State Transitions
PAID
→ REFUND_REQUESTED
→ REFUND_PROCESSING
→ REFUNDED
PAID
→ REFUND_REQUESTED
→ REFUND_FAILED
## Events
- `RefundRequested`
- `RefundCompleted`
- `RefundFailed`
## Failure Modes
- Duplicate request.
- Payment provider timeout.
- Event publish failure.
- Audit write failure.
- Admin UI reads stale status.
## Open Questions
- Are multiple partial refunds allowed?
- Is approval required above a threshold?
- What is the SLA for status visibility?
כאן כבר יש לנו artifact. לא לצ׳אט. לא ״סיכמנו בעל פה״. קובץ.
שלב 4: Engineering review עם gstack
לפני design מפורט, נריץ review הנדסי.
/plan-eng-review
Review .lattice/requirements/refund-workflow.md.
Focus on:
- data model implications
- transaction boundaries
- event publishing guarantees
- idempotency
- race conditions
- rollback behavior
- observability
- test matrix
Do not write implementation code.
Produce engineering risks and required design decisions.
השלב הזה אמור לייצר דברים כמו:
# Engineering Review Notes
## Critical Decisions
1. Refund request creation and audit write must be atomic.
2. Event publishing should use outbox pattern or equivalent reliability mechanism.
3. Refund request must use idempotency key scoped by invoice and request source.
4. Admin status should read from refund state stored internally, not directly from provider.
5. Provider timeout must not imply failure; status reconciliation is required.
## Race Conditions
- Two admins request refund for same invoice simultaneously.
- Provider callback arrives before local state transition completes.
- Retry publishes duplicate RefundRequested event.
## Required Tests
- Full refund success.
- Partial refund success.
- Duplicate refund request.
- Refund exceeds paid amount.
- Provider timeout.
- Event publish retry.
- Audit trail write failure.
שימו לב מה קרה כאן: עוד לא נכתוב קוד, אבל כבר גילינו את רוב המקומות שבהם feature כזה יכול להישבר. וזה בדיוק
וזה בדיוק ה-ROI של process.
שלב 5: Design Blueprint עם Lattice.
עכשיו אפשר לעבור ל-design:
/design-blueprint
Create a design blueprint for .lattice/requirements/refund-workflow.md.
Use:
- .lattice/standards/architecture.md
- .lattice/standards/secure-coding.md
- .lattice/learnings/operational-learnings.md
- engineering review notes from /plan-eng-review
Do not write implementation code.
The blueprint must include:
- capabilities
- components
- interactions
- contracts
- data model changes
- state machine
- failure handling
- test strategy
פלט מקוצר:
# Refund Workflow Design Blueprint
## Components
### HTTP Interface
`POST /admin/invoices/:invoiceId/refunds`
Responsibilities:
- Authenticate admin.
- Validate request shape.
- Delegate to application use-case.
- Return refund request id and initial status.
Must not:
- Query PostgreSQL directly.
- Call payment provider directly.
- Publish events directly.
### Application Use-Case
`RequestRefundUseCase`
Responsibilities:
- Load invoice.
- Validate business rules.
- Create refund request.
- Write audit record.
- Persist outbox event.
- Return refund status.
### Domain
`InvoiceRefundPolicy`
Responsibilities:
- Validate refund eligibility.
- Validate partial refund limits.
- Prevent invalid state transitions.
### Infrastructure
- `RefundRepository`
- `AuditLogRepository`
- `OutboxRepository`
- `PaymentProviderRefundClient`
## Consistency Model
Refund request creation, audit write, and outbox event creation occur in one database transaction.
Actual provider call is asynchronous and triggered by outbox processing.
## Idempotency
Idempotency key is required per request.
Scope:
`adminId + invoiceId + idempotencyKey`
## Failure Handling
- Provider timeout leaves refund in `REFUND_PROCESSING`.
- Reconciliation job resolves unknown provider states.
- Outbox retry is safe because event handling is idempotent.
- Duplicate admin requests return existing refund request when idempotency key matches.
זה המקום שבו design-first באמת משתלם. הקוד שייכתב אחר כך כבר לא צריך ״להמציא ארכיטקטורה״. הוא צריך לממש החלטה.
שלב 6: Code Forge עם Lattice
רק עכשיו מגיעים לקוד:
/code-forge
Implement the approved refund workflow design blueprint.
Use:
- .lattice/context/refund-workflow-design-blueprint.md
- .lattice/standards/architecture.md
- .lattice/standards/clean-code.md
- .lattice/standards/test-quality.md
- .lattice/standards/secure-coding.md
Rules:
- Implement only the approved design.
- Do not modify unrelated modules.
- Do not introduce new architectural patterns.
- Generate tests with the implementation.
- Stop if existing code contradicts the approved design.
זו הוראה הרבה יותר בטוחה מ-"build refund workflow״.
היא אומרת ל-AI:
אתה לא עושה product discovery עכשיו.
אתה לא מחליף ארכיטקטורה
אתה לא עושה refactor צדדי.
אתה לא משנה public contracts בלי אישור
אתה מממש design שאושר.
במילים אחרות: ברוך הבא להנדסת תוכנה, חבר רובוטי יקר.
שלב 7: Review משולב
אחרי המימוש, מפעילים review בשתי שכבות.
קודם gstack:
/review
Review the implementation delta.
Focus on:
- production bugs
- hidden assumptions
- scope creep
- missing tests
- incorrect error handling
- race conditions
- security issues
Classify findings by severity.
ואז Lattice:
/review
Review the implementation against:
- .lattice/standards/architecture.md
- .lattice/standards/secure-coding.md
- .lattice/standards/test-quality.md
- .lattice/context/refund-workflow-design-blueprint.md
Persist reusable findings into:
.lattice/reviews/refund-workflow-review.md
.lattice/learnings/operational-learnings.md
ההבדל עדין אבל חשוב.
gstack עוזר לבדוק את השינוי כתהליך shipping.
Lattice בודק את השינוי מול סטנדרטים וקונטקסט קיימים.
פלט טוב יכול להיראות ככה:
# Review Findings
## High Severity
### Missing idempotency enforcement in worker
The HTTP layer validates idempotency key, but the worker does not enforce
deduplication when consuming RefundRequested.
Impact:
Duplicate event delivery may trigger duplicate provider calls.
Required fix:
Persist provider operation key and enforce uniqueness before calling provider.
## Medium Severity
### Audit trail does not include actor role
Refund audit records include admin id but not admin role.
Required fix:
Include role and permission context in audit metadata.
## Learning
For money movement workflows, idempotency must be enforced both at request
creation and at asynchronous execution boundary.
ה-Learning האחרון הוא הזהב. כי אם הוא נשמר ב- .lattice/learnings/operational-learnings.md, הוא יכול להשפיע על הפיצ׳ר הבא.
זה ההבדל בין AI שעוזר פעם אחת לבין AI workflow שמשתפר לאורך זמן.
אנליזה
היתרון המרכזי של gstack ו-Lattice הוא לא שהם ״כותבים קוד יותר טוב״. זו טענה קצת שטוחה מדי.
היתרון האמיתי הוא שהם מקטינים את כמות ההחלטות הסמויות שה-AI מקבל לבד.
וזו בדיוק הבעיה בעבודה עם AI coding agents: הם לא רק כותבים קוד. הם מקבלים החלטות. לפעמים החלטות קטנות, כמו שם של פונקציה. לפעמים החלטות גדולות, כמו איפה לשים business logic או איך לטפל ב-retry.
כאשר אין תהליך, ההחלטות האלה קורות בשקט.
כאשר יש gstack ו-Lattice, ההחלטות עוברות דרך שלבים, סטדנרטים ו-artifacts.
קונטקסט הוא חומר גלם, לא מערכת
קונטקסט חשוב מאוד. בלי קונטקסט, ה-AI מנחש. אבל קונטקסט לבדו לא אומר ל-AI מה לעשות קודם, מתי לעצור, איזה artifact להפיק, או מתי צריך review.
אפשר לתת ל-AI את כל הריפו ועדיין לקבל design גרוע.
למה? כי לראות את כל הקוד לא אומר להבין את כל הסיבות שבגללן הקוד נראה כמו שהוא נראה.
חלק מהסיבות נמצאות ב-ADRs.
חלק מהסיבות מקורן בתקריות בפרודקשיין.
חלק היו בתהליך ה-review.
חלק נמצאות בהחלטות פרודטק.
וחלק, כמובן, נמצאות בראש של הסניור שממלמל ״לא שוב האדפטר הזה״.
Lattice מנסה להפוך את הידע הזה לקונטקסט חי.
gstack מנסה להכניס אותו לתוך תהליך.
השילוב ביניהם אומר: לא רק ״הנה כל המידע״, אלא ״הנה איך עובדים עם המידע״.
Durable artifacts מנצחים שיחות ארוכות
אחת הבעיות הגדולות בעבודה עם AI היא context erosion. בתחילת השיחה מתקבלת החלטה. אחרי עשרים הודעות, שלושה תיקנים ושני logs, ההחלטה נעלמת לתוך רעש.
המודל אולי עדיין ״רואה״ אותה טכנית, אבל בפועל היא מאבדת משקל.
לכן artifacts חשובים כל כך
requirement.md
design-blueprint.md
architecture.md
review-log.md
operational-learnings.md
קבצים כאלה משנים את אופי העבודה. הם מאפשרים ל-AI לחזור להחלטות מפורשות במקום להסתמך על זיכרון שיחה.
זה בדיוק ההבדל בין: "אמרנו לו לא לעשות את זה״ לבין ״“זה כתוב ב־architecture standards והוא נבדק מול זה”.
הראשון הוא תקווה, השני הוא תהליך
Design first הוא לא בירוקרטיה; הוא מנגנון הגנה
AI טוב מאוד בלקפוץ למימוש. לפעמים טוב מדי.
הבעיה היא שרוב הטעויות היקרות לא נראות כמו syntax error. הן נראות כמו design שנראה סביר עד שהוא פוגש פרודקשיין.
Design-First לא נועד להאט. הוא נועד למנוע מהירות בכיוון הלא נכון.
Lattice עושה את זה דרך design-blueprint.
gstack עושה את זה דרך planning ו-engineering review.
שניהם מנסים להכריח את השאלה החשובה לפני הקוד:
האם אנחנו בכלל בונים את הדבר הנכון, בצורה הנכוה?
כן, זה פחות מרגש מ-diff ענק שנוצר תוך דקה.
אבל גם אירוע בפרודקשיין פחות מרגש כשמנועים אותו מראש.
Role separation מפחית רעש
gstack מעניין כי הוא מבין שמשימות שונות דורשות mode שונה של חשיבה.
לחשוב על scope מוצרי זה לא אותו דבר כמו לכתוב קוד.
לתכנן ארכיטקטורה זה לא אותו דבר כמו לבדוק UI.
לעשות review זה לא אותו דבר כמו להכין release summary.
כאשר אותו פרומפט מנסה לעשות הכל, התוצאה מתערבבת. ה-AI יכול לקפוץ משיקולי product לשמות משתנים, משם ל-test strategy, ומשם ל-refactor לא קשור. זה מרגיש פרודוקטיבי, אבל בפעול קשה לשלוט בזה.
gstack מפריד:
Product thinking → האם הבעיה נכונה?
Engineering planning → האם המבנה נכון?
Implementation → האם הקוד מממש את ההחלטה?
Review → האם הדלתא בטוחה?
QA → האם ההתנהגות עובדת?
Ship → האם אפשר לשחרר?
Reflect → מה למדנו לפעם הבאה?
ההפרדה הזו חשובה במיוחד כשעובדים על פיצ׳רים גדולים. היא מקטינה עומס קוגניטיבי ומייצרת צ׳קפוינט טבעיים.
סטנדרטים צריכים להיות דינאמיים, לא מסמך קפוא
Lattice חזק במיוחד ברעיון של סטנדרטים כמערכת נושמת.
אבל כאן יש גם סיכון: סטנדרט שלא מתוחזק הופך להיות legacy policy. וכמו כל לגאסי, הוא מתחיל בתור ״רק זמנית״ ומסתיים בזה שמישהו מפחד למחוק קובץ כי אולי פרודקשיין תלוי בו רגשית.
אם .lattice/standards/architecture.md לא מתעדכן, ה-AI יאכוף מציאות ישנה. זה מסוכן יותר ממצב שלי סטנדרטים, כי זה נותן תחשות ביטחון מזויפת.
לכן צריך להתייחס ל.lattice כמו לכל קוד תשתיתי אחר:
לעשות review לשינויים.
לעדכן אחרי refactor גדולים
להוסיף מסקנות אחרי כל באג
למחוק כללים שכבר לא נכונים
לוודא שהסטנדרטים לא סותרים זה את זה.
במילים אחרות: אם ה-AI עובד לפי מסמכים, המסמכים הם חלק מהמערכת.
לולאת פידבק היא היתרון המצטבר
החלק הכי מעניין ב-Lattice הוא לא רק הסטנדרטים, אלא הלמידה.
כל באג, תקרית, review או מקרה קצה שמגלים יכול להפוך לידע שמוזן למחזור פיתוח הבא.
לדוגמה, אחרי שגילינו שחסר idempotency ב-worker, אפשר להוסיף ל-operational learning:
## Money Movement Learning
For workflows involving money movement, idempotency must be enforced at every
asynchronous boundary, not only at the initial HTTP request boundary.
Check:
- HTTP request deduplication
- queue consumer deduplication
- provider operation key
- reconciliation behavior
בפעם הבאה שנבנה flow פיננסי, ה-AI לא יתחיל מאפס. הוא מקבל את הלקח הזה כחלק מה-context.
זה בדיוק המקום שבו AI workflow מתחיל להרגיש כמו מערכת לומדת - לא במובן המיסטי של ״המודל למד״, אלא במובן ההנדסי הפשוט: הריפו צבר ידע, והכלים שלנו קוראים אותו.
Failure modes שצריך לקחת ברצינות
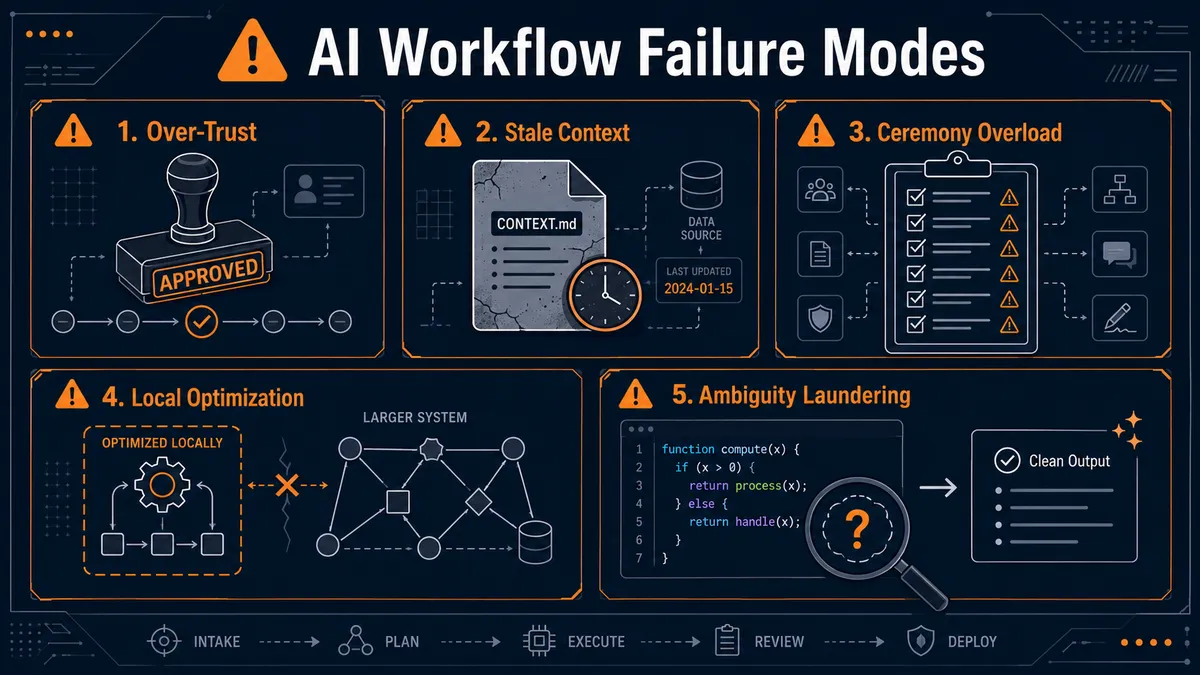
ה-failure mode הראשון הוא over trust.
פקודה בשם /review לא מבטיחה review איכותי. היא רק מפעילה תהליך. באזורים כמו אבטחה, כספים, פרטיות, הרשאות, data migrations - האדם עדיין אחראי.
גם בתחומים אחרים הוא עדיין אחראי אבל באלו זה אדרבא ואדרבא.
ה-failure mode השני הוא stale context.
אם הסטנדרטים לא מעודכנים, ה-AI יעבוד לפי עבר שלא קיים.
השלישי הוא ceremony overload.
לא כל שינוי צריך full workflow. תיקון type לא צריך מסמך דרישות, מסמך דיזיין, engineering review ו-QA. צריך להתאים את עומק התהליך לסיכון.
הרביעי הוא local optimization.
AI יכול לשפר קובץ אחד ולפגוע במבנה המערכת. לכן review חייב להיות עם הסתכלות מערכתית, לא רק על הdiff הספציפי.
החמישי הוא ambiguity laundering.
כשאין מספיק מידע, AI עלול להפוך הנחה להחלטה. framework טוב צריך לגרום לו לעצור, להציג ambiguity ולבקש הכרעה.
וזה אולי הכלל החשוב ביותר בעבודה עם AI:
AI שלא יודע - צריך לעצור.
AI שמנחש בשקט - צריך guardrail.
סיכום
gstack ו-Lattice מייצגות מעבר חשוב בעבודה עם AI בפיתוח תוכנה.
לא עוד רק פרומפט טוב יותר
לא עוד רק קונטקסט גדול יותר.
אלא workflow הנדסי שמנסה להכניס את ה-AI לתוך אותם מנגנונים שצוותים טובים כבר משתמשים בהם: דרישות, סטנדרטים, code review, QA, shipping, ולמידה
gstack נותן את שכבת התהליך:
Think → Plan → Build → Review → Test → Ship → Learn
Lattice נותן את שכבת הזיכרון והסטנדרטים:
Atoms → Molecules → Refiners → .lattice/ living context
ביחד הם יוצרים כיוון ברור: AI-assisted development מתקדם מ־chat-based coding ל־process-aware engineering.
וזה שינוי משמעותי, כי הבעיה האמיתית כבר לא רק “האם AI יכול לכתוב קוד”. ברור שהוא יכול. השאלה היא האם הוא יכול לעבוד בתוך גבולות מערכתיים, לשמר החלטות, להפעיל standards, לעצור כשיש ambiguity, ולהשאיר אחריו ידע שמשפר את המחזור הבא.
או בניסוח של שורת קוד:
AI שכותב קוד זה נחמד.
AI שעובד לפי תהליך, מכבד architecture, שומר learnings, ויודע מתי לא לכתוב קוד — זה כבר מתחיל להיראות כמו הנדסה.